SVM算法的理解及其Python实现多分类和二分类问题
Jeremy_lf 人气:0原理
SVM被提出于1964年,在二十世纪90年代后得到快速发展并衍生出一系列改进和扩展算法,在人像识别、文本分类等模式识别(pattern recognition)问题中有得到应用。
支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning) 方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane)
SVM可以通过核方法(kernel method)进行非线性分类,是常见的核学习(kernel learning)方法之一。
分类理论
在分类问题中给定输入数据和学习目标:X = { X1, X2,…Xn },Y = { y1,y2,…yn}。
其中输入数据的每个样本都包含多个特征并由此构成特征空间(feature space):Xi = { x1,x2…xn} ,而学习目标为二元变量 y { − 1 , 1 } y\{-1,1\} y{−1,1}表示负类(negative class)和正类(positive class)。
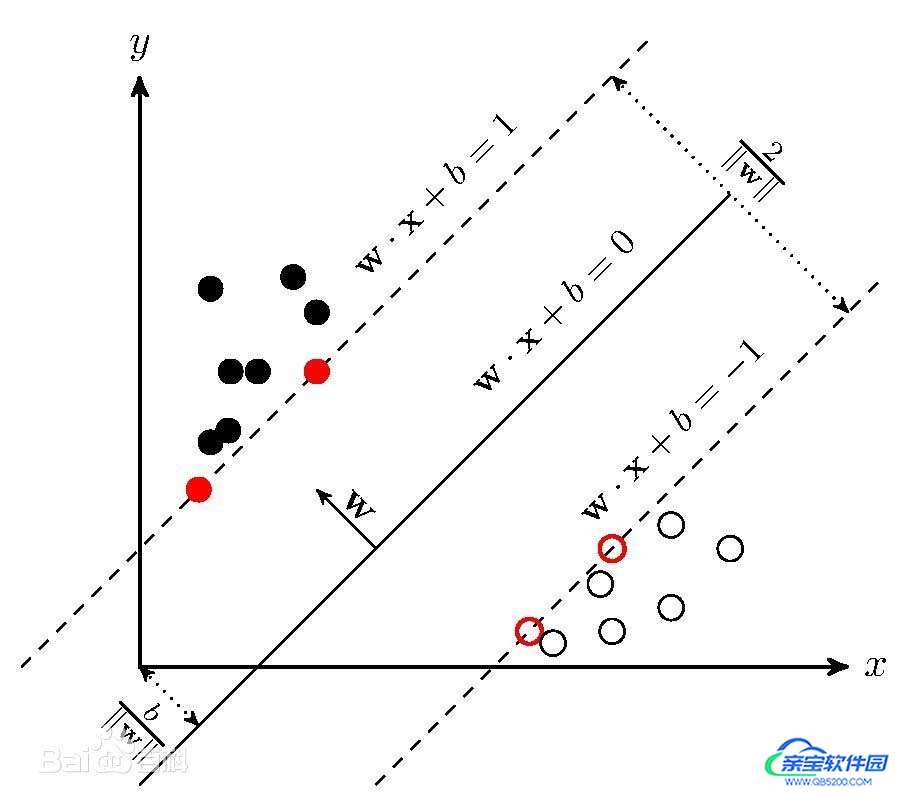
若输入数据所在的特征空间存在作为决策边界(decision boundary)的超平面将学习目标按正类和负类分开,并使任意样本的点到平面距离大于等于1,则称该分类问题具有线性可分性,参数 w,b分别为超平面的法向量和截距。

满足该条件的决策边界实际上构造了2个平行的超平面作为间隔边界以判别样本的分类:
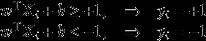
所有在上间隔边界上方的样本属于正类,在下间隔边界下方的样本属于负类。
两个间隔边界的距离 d = 2 ∥ w ∥ d=\frac{2}{\|w\|} d=∥w∥2被定义为边距(margin),位于间隔边界上的正类和负类样本为支持向量(support vector)。
确定最大间距

SVM多分类
SVM算法最初是为二值分类问题设计的,当处理多类问题时,就需要构造合适的多类分类器。
目前,构造SVM多类分类器的方法主要有两类:
- 一类是直接法,直接在目标函数上进行修改,将多个分类面的参数求解合并到一个最优化问题中,通过求解该最优化问题“一次性”实现多类分类。这种方法看似简单,但其计算复杂度比较高,实现起来比较困难,只适合用于小型问题中;
- 另一类是间接法,主要是通过组合多个二分类器来实现多分类器的构造,常见的方法有one-against-one和one-against-all两种。
a.一对多法(one-versus-rest,简称1-v-r-SVMs)。
- 训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样k个类别的样本就构造出了k个SVM。分类时将未知样本分类为具有最大分类函数值的那类。
b.一对一法(one-versus-one,简称1-v-1 SVMs)。
- 其做法是在任意两类样本之间设计一个SVM,因此k个类别的样本就需要设计k(k-1)/2个SVM。当对一个未知样本进行分类时,最后得票最多的类别即为该未知样本的类别。Libsvm中的多类分类就是根据这个方法实现的。
Python实现
多分类
X_train, X_test, y_train, y_test = train_test_split(feature, label, test_size=.2,random_state=0)
# 训练模型
model = OneVsRestClassifier(svm.SVC(kernel='linear',probability=True,random_state=random_state))
print("[INFO] Successfully initialize a new model !")
print("[INFO] Training the model…… ")
clt = model.fit(X_train,y_train)
print("[INFO] Model training completed !")
# 保存训练好的模型,下次使用时直接加载就可以了
joblib.dump(clt,"F:/python/model/conv_19_80%.pkl")
print("[INFO] Model has been saved !")
y_test_pred = clt.predict(X_test)
ov_acc = metrics.accuracy_score(y_test_pred,y_test)
print("overall accuracy: %f"%(ov_acc))
print("===========================================")
acc_for_each_class = metrics.precision_score(y_test,y_test_pred,average=None)
print("acc_for_each_class:\n",acc_for_each_class)
print("===========================================")
avg_acc = np.mean(acc_for_each_class)
print("average accuracy:%f"%(avg_acc))
二分类
>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
>>> y = np.array([1, 1, 2, 2])
>>> from sklearn.svm import SVC
>>> clf = SVC()
>>> clf.fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> print(clf.predict([[-0.8, -1]]))
[1]
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
加载全部内容