一文带你深度解密Python的字节码
古明地觉 人气:0楔子
当我们想要执行一个 py 文件的时候,只需要在命令行中输入 python xxx.py 即可,但你有没有想过这背后的流程是怎样的呢?
首先 py 文件不是一上来就直接执行的,而是会先有一个编译的过程,整个步骤如下:
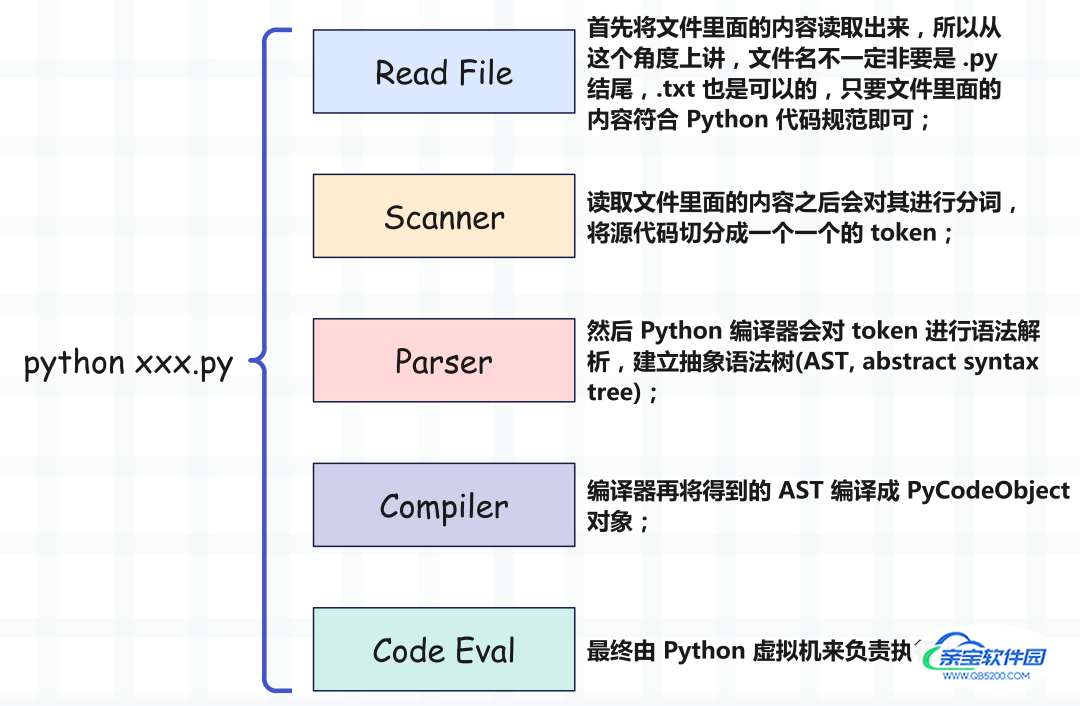
这里我们看到了 Python 编译器、Python 虚拟机,而且我们平常还会说 Python 解释器,那么三者之间有什么区别呢?

Python 编译器负责将 Python 源代码编译成 PyCodeObject 对象,然后交给 Python 虚拟机来执行。
那么 Python 编译器和 Python 虚拟机都在什么地方呢?如果打开 Python 的安装目录,会发现有一个 python.exe,点击的时候会通过它来启动一个终端。

但问题是这个文件大小还不到 100K,不可能容纳一个编译器加一个虚拟机,所以下面还有一个 python38.dll。没错,编译器、虚拟机都藏身于 python38.dll 当中。
因此 Python 虽然是解释型语言,但也有编译的过程。源代码会被编译器编译成 PyCodeObject 对象,然后再交给虚拟机来执行。而之所以要存在编译,是为了让虚拟机能更快速地执行,比如在编译阶段常量都会提前分配好,而且还可以尽早检测出语法上的错误。
pyc 文件是什么
在 Python 开发时,我们肯定都见过这个 pyc 文件,它一般位于 __pycache__ 目录中,那么 pyc 文件和 PyCodeObject 之间有什么关系呢?
首先我们都知道字节码,虚拟机的执行实际上就是对字节码不断解析的一个过程。然而除了字节码之外,还应该包含一些其它的信息,这些信息也是 Python 运行的时候所必需的,比如常量、变量名等等。
我们常听到 py 文件被编译成字节码,这句话其实不太严谨,因为字节码只是一个 PyBytesObject 对象、或者说一段字节序列。但很明显,光有字节码是不够的,还有很多的静态信息也需要被收集起来,它们整体被称为 PyCodeObject。
而 PyCodeObject 对象中有一个成员 co_code,它是一个指针,指向了这段字节序列。但是这个对象除了有 co_code 指向的字节码之外,还有很多其它成员,负责保存代码涉及到的常量、变量(名字、符号)等等。
但是问题来了,难道每一次执行都要将源文件编译一遍吗?如果没有对源文件进行修改的话,那么完全可以使用上一次的编译结果。相信此时你能猜到 pyc 文件是干什么的了,它就是负责保存编译之后的 PyCodeObject 对象。
所以我们知道了,pyc 文件里面的内容是 PyCodeObject 对象。对于 Python 编译器来说,PyCodeObject 对象是对源代码编译之后的结果,而 pyc 文件则是这个对象在硬盘上的表现形式。
当下一次运行的时候,Python 会根据 pyc 文件中记录的编译结果直接建立内存中的 PyCodeObject 对象,而不需要再重新编译了,当然前提是没有对源文件进行修改。
PyCodeObject 底层结构
我们来看一下这个结构体长什么样子,它的定义位于 Include/code.h 中。
typedef struct {
//头部信息,我们看到真的一切皆对象,字节码也是个对象
PyObject_HEAD
//可以通过位置参数传递的参数个数
int co_argcount;
//只能通过位置参数传递的参数个数,Python3.8新增
int co_posonlyargcount;
//只能通过关键字参数传递的参数个数
int co_kwonlyargcount;
//代码块中局部变量的个数,也包括参数
int co_nlocals;
//执行该段代码块需要的栈空间
int co_stacksize;
//参数类型标识
int co_flags;
//代码块在文件中的行号
int co_firstlineno;
//指令集,也就是字节码,它是一个bytes对象
PyObject *co_code;
//常量池,一个元组,保存代码块中的所有常量
PyObject *co_consts;
//一个元组,保存代码块中引用的其它作用域的变量
PyObject *co_names;
//一个元组,保存当前作用域中的变量
PyObject *co_varnames;
//内层函数引用的外层函数的作用域中的变量
PyObject *co_freevars;
//外层函数的作用域中被内层函数引用的变量
//本质上和co_freevars是一样的
PyObject *co_cellvars;
//无需关注
Py_ssize_t *co_cell2arg;
//代码块所在的文件名
PyObject *co_filename;
//代码块的名字,通常是函数名、类名,或者文件名
PyObject *co_name;
//字节码指令与python源代码的行号之间的对应关系
//以PyByteObject的形式存在
PyObject *co_lnotab;
} PyCodeObject;这里面的每一个成员,我们一会儿都会逐一演示进行说明。总之 Python 编译器在对源代码进行编译的时候,对于代码中的每一个 block,都会创建一个 PyCodeObject 与之对应。
但多少代码才算得上是一个 block 呢?事实上,Python 有一个简单而清晰的规则:当进入一个新的名字空间,或者说作用域时,就算是进入了一个新的 block 了。举个例子:
class A: a = 123 def foo(): a = []
我们仔细观察一下上面这个文件,它在编译完之后会有三个 PyCodeObject 对象,一个是对应整个 py 文件(模块)的,一个是对应 class A 的,一个是对应 def foo 的。因为这是三个不同的作用域,所以会有三个 PyCodeObject 对象。
所以一个 code block 对应一个作用域、同时也对应一个 PyCodeObject 对象。Python 的类、函数、模块都有自己独立的作用域,因此在编译时也都会有一个 PyCodeObject 对象与之对应。
PyCodeObject 代码演示
PyCodeObject 我们知道它是干什么的了,那如何才能拿到这个对象呢?首先该对象在 Python 里面的类型是 <class 'code'>,但是底层没有将这个类暴露给我们,因此 code 这个名字在 Python 里面只是一个没有定义的变量罢了。
但是我们可以通过其它的方式进行获取,比如函数。
def func(): pass print(func.__code__) # <code object ...... print(type(func.__code__)) # <class 'code'>
我们可以通过函数的 __code__ 属性拿到底层对应的PyCodeObject对象,当然也可以获取里面的成员,我们来演示一下。
co_argcount:可以通过位置参数传递的参数个数
def foo(a, b, c=3): pass print(foo.__code__.co_argcount) # 3 def bar(a, b, *args): pass print(bar.__code__.co_argcount) # 2 def func(a, b, *args, c): pass print(func.__code__.co_argcount) # 2
foo 中的参数 a、b、c 都可以通过位置参数传递,所以结果是 3;对于 bar,则是两个,这里不包括 *args;而函数 func,显然也是两个,因为参数 c 只能通过关键字参数传递。
co_posonlyargcount:只能通过位置参数传递的参数个数,Python3.8 新增
def foo(a, b, c): pass print(foo.__code__.co_posonlyargcount) # 0 def bar(a, b, /, c): pass print(bar.__code__.co_posonlyargcount) # 2
注意:这里是只能通过位置参数传递的参数个数。对于 foo 而言,里面的三个参数既可以通过位置参数、也可以通过关键字参数传递;而函数 bar,里面的 a、b 只能通过位置参数传递。
co_kwonlyargcount:只能通过关键字参数传递的参数个数
def foo(a, b=1, c=2, *, d, e): pass print(foo.__code__.co_kwonlyargcount) # 2
这里是 d 和 e,它们必须通过关键字参数传递。
co_nlocals:代码块中局部变量的个数,也包括参数
def foo(a, b, *, c): name = "xxx" age = 16 gender = "f" c = 33 print(foo.__code__.co_nlocals) # 6
局部变量有 a、b、c、name、age、gender,所以我们看到在编译之后,函数的局部变量就已经确定了,因为它们是静态存储的。
co_stacksize:执行该段代码块需要的栈空间
def foo(a, b, *, c): name = "xxx" age = 16 gender = "f" c = 33 print(foo.__code__.co_stacksize) # 1
这个暂时不需要太关注。
co_flags:参数类型标识
标识函数的参数类型,如果一个函数的参数出现了 *args,那么 co_flags & 0x04 为真;如果一个函数的参数出现了 **kwargs,那么 co_flags & 0x08 为真;
def foo1(): pass # 结果全部为假 print(foo1.__code__.co_flags & 0x04) # 0 print(foo1.__code__.co_flags & 0x08) # 0 def foo2(*args): pass # co_flags & 0x04 为真,因为出现了 *args print(foo2.__code__.co_flags & 0x04) # 4 print(foo2.__code__.co_flags & 0x08) # 0 def foo3(*args, **kwargs): pass # 显然 co_flags & 0x04 和 co_flags & 0x08 均为真 print(foo3.__code__.co_flags & 0x04) # 4 print(foo3.__code__.co_flags & 0x08) # 8
当然啦,co_flags 可以做的事情并不止这么简单,它还能检测一个函数的类型。比如函数内部出现了 yield,那么它就是一个生成器函数,调用之后可以得到一个生成器;使用 async def 定义,那么它就是一个协程函数,调用之后可以得到一个协程。
这些在词法分析的时候就可以检测出来,编译之后会体现在 co_flags 这个成员中。
# 如果是生成器函数 # 那么 co_flags & 0x20 为真 def foo1(): yield print(foo1.__code__.co_flags & 0x20) # 32 # 如果是协程函数 # 那么 co_flags & 0x80 为真 async def foo2(): pass print(foo2.__code__.co_flags & 0x80) # 128 # 显然 foo2 不是生成器函数 # 所以 co_flags & 0x20 为假 print(foo2.__code__.co_flags & 0x20) # 0 # 如果是异步生成器函数 # 那么 co_flags & 0x200 为真 async def foo3(): yield print(foo3.__code__.co_flags & 0x200) # 512 # 显然它不是生成器函数、也不是协程函数 # 因此和 0x20、0x80 按位与之后,结果都为假 print(foo3.__code__.co_flags & 0x20) # 0 print(foo3.__code__.co_flags & 0x80) # 0
在判断函数种类时,这种方式是最优雅的。
co_firstlineno:代码块在对应文件的起始行
def foo(a, b, *, c): pass # 显然是文件的第一行 # 或者理解为 def 所在的行 print(foo.__code__.co_firstlineno) # 1
如果函数出现了调用呢?
def foo(): return bar def bar(): pass print(foo().__code__.co_firstlineno) # 4
如果执行 foo,那么会返回函数 bar,最终得到的就是 bar 的字节码,因此最终结果是 def bar(): 所在的行数。所以每个函数都有自己的作用域,以及 PyCodeObject 对象。
co_names:符号表,一个元组,保存代码块中引用的其它作用域的变量
c = 1
def foo(a, b):
print(a, b, c)
d = (list, int, str)
print(
foo.__code__.co_names
) # ('print', 'c', 'list', 'int', 'str')一切皆对象,但看到的都是指向对象的变量,所以 print, c, list, int, str 都是变量,它们都不在当前 foo 函数的作用域中。
co_varnames:符号表,一个元组,保存在当前作用域中的变量
c = 1
def foo(a, b):
print(a, b, c)
d = (list, int, str)
print(foo.__code__.co_varnames) # ('a', 'b', 'd')a、b、d 是位于当前 foo 函数的作用域当中的,所以编译阶段便确定了局部变量是什么。
co_consts:常量池,一个元组,保存代码块中的所有常量
x = 123
def foo(a, b):
c = "abc"
print(x)
print(True, False, list, [1, 2, 3], {"a": 1})
return ">>>"
print(
foo.__code__.co_consts
) # (None, 'abc', True, False, 1, 2, 3, 'a', '>>>')co_consts 里面出现的都是常量,但 [1, 2, 3] 和 {"a": 1} 却没有出现,由此我们可以得出,列表和字典绝不是在编译阶段构建的。编译时,只是收集了里面的元素,然后等到运行时再去动态构建。
不过问题来了,在构建的时候解释器怎么知道是要构建列表、还是字典、亦或是其它的什么对象呢?所以这就依赖于字节码了,解释字节码的时候,会判断到底要构建什么样的对象。
因此解释器执行的是字节码,核心逻辑都体现在字节码中。但是光有字节码还不够,它包含的只是程序的主干逻辑,至于变量、常量,则从符号表和常量池里面获取。
co_name:代码块的名字
def foo(): pass # 这里就是函数名 print(foo.__code__.co_name) # foo
co_code:字节码
def foo(a, b, /, c, *, d, e): f = 123 g = list() g.extend([tuple, getattr, print]) print(foo.__code__.co_code) #b'd\x01}\x05t\x00\x83\x00}\x06|\x06......'
这便是字节码,它只保存了要操作的指令,因此光有字节码是肯定不够的,还需要其它的静态信息。显然这些信息连同字节码一样,都位于 PyCodeObject 中。
字节码与反编译
Python 执行源代码之前会先编译得到 PyCodeObject 对象,里面的 co_code 指向了字节码序列。
虚拟机会根据这些字节码序列来进行一系列的操作(当然也依赖其它的静态信息),从而完成对程序的执行。
每个操作都对应一个操作指令、也叫操作码,总共有120多种,定义在 Include/opcode.h 中。
#define POP_TOP 1 #define ROT_TWO 2 #define ROT_THREE 3 #define DUP_TOP 4 #define DUP_TOP_TWO 5 #define NOP 9 #define UNARY_POSITIVE 10 #define UNARY_NEGATIVE 11 #define UNARY_NOT 12 #define UNARY_INVERT 15 #define BINARY_MATRIX_MULTIPLY 16 #define INPLACE_MATRIX_MULTIPLY 17 #define BINARY_POWER 19 #define BINARY_MULTIPLY 20 #define BINARY_MODULO 22 #define BINARY_ADD 23 #define BINARY_SUBTRACT 24 #define BINARY_SUBSCR 25 #define BINARY_FLOOR_DIVIDE 26 #define BINARY_TRUE_DIVIDE 27 #define INPLACE_FLOOR_DIVIDE 28 // ... // ...
操作指令只是一个整数,然后我们可以通过反编译的方式查看每行 Python 代码都对应哪些操作指令:
# Python中的dis模块专门负责干这件事情 import dis def foo(a, b): c = a + b return c # 里面接收一个字节码 # 当然函数也是可以的,会自动获取co_code dis.dis(foo) """ 5 0 LOAD_FAST 0 (a) 2 LOAD_FAST 1 (b) 4 BINARY_ADD 6 STORE_FAST 2 (c) 6 8 LOAD_FAST 2 (c) 10 RETURN_VALUE """
字节码反编译后的结果多么像汇编语言,其中第一列是源代码行号,第二列是字节码偏移量,第三列是操作指令(也叫操作码),第四列是指令参数(也叫操作数)。Python 的字节码指令都是成对出现的,每个指令都会带有一个指令参数。
查看字节码也可以使用 opcode 模块:
from opcode import opmap
opmap = {v: k for k, v in opmap.items()}
def foo(a, b):
c = a + b
return c
code = foo.__code__.co_code
for i in range(0, len(code), 2):
print("操作码: {:<12} 操作数: {}".format(
opmap[code[i]], code[i+1]
))
"""
操作码: LOAD_FAST 操作数: 0
操作码: LOAD_FAST 操作数: 1
操作码: BINARY_ADD 操作数: 0
操作码: STORE_FAST 操作数: 2
操作码: LOAD_FAST 操作数: 2
操作码: RETURN_VALUE 操作数: 0
"""总之字节码就是一段字节序列,转成列表之后就是一堆数字。偶数位置表示指令本身,而每个指令后面都会跟一个指令参数,也就是奇数位置表示指令参数。
所以指令本质上只是一个整数:

虚拟机会根据不同的指令执行不同的逻辑,说白了 Python 虚拟机执行字节码的逻辑就是把自己想象成一颗 CPU,并内置了一个巨型的 switch case 语句,其中每个指令都对应一个 case 分支。
然后遍历整条字节码,拿到每一个指令和指令参数。然后对指令进行判断,不同的指令进入不同的 case 分支,执行不同的处理逻辑,直到字节码全部执行完毕或者程序出错。
加载全部内容